A Language Model Built for German, Designed to Run Locally
Most large language models treat German as an afterthought. They are trained predominantly on English text, with German mixed into a multilingual soup alongside dozens of other languages. The result: German works, but it does not work well. Compound words get fragmented. Morphology gets mangled. Token efficiency suffers, which means higher costs and shorter usable context.
We built Faust-1 to change that.
Faust-1 is a 1.6B parameter language model trained entirely from scratch with German as the primary language. Not fine-tuned from an English model. Not adapted from a multilingual base. Built from the ground up with German syntax, compounding, morphology, and reasoning patterns as the default operating regime.
And it runs on your laptop.
Why German-First Matters
When a model is trained primarily on English and then evaluated on German, several things go wrong.
Tokenization is inefficient. Standard tokenizers split German compound words into fragments that make no linguistic sense. “Krankenversicherungsbeitrag” (health insurance contribution) might become five or six tokens. Each extra token costs compute, reduces effective context length, and introduces fragmentation that the model has to work around.
Syntax is mismodeled. German word order is fundamentally different from English. Verb-final clauses, separable prefixes, and complex noun phrases require a model that has seen enough German text to internalize these patterns — not one that treats them as edge cases.
Reasoning patterns differ. The way information is structured, arguments are built, and conclusions are drawn in German text follows different conventions. A model that has primarily learned to reason through English text will produce German that reads like a translation.
Faust-1 addresses all of this by making German the primary training language, representing approximately 90% of the training corpus.
What We Built
Faust-1 is a decoder-only causal language model with 1.6B parameters. The development process covers the full pipeline:
- Large-scale data collection with synthetic data generation
- Data cleaning, normalization, and deduplication to reduce contamination and redundancy
- Pre-training on a predominantly German corpus using a decoder-only language modeling objective
- Supervised post-training (instruction tuning) using labeled input-output pairs for conversational and task-oriented use
- Preference-based optimization including Direct Preference Optimization (DPO) to improve response quality and alignment
The result is a conversational model that understands and generates German at a level you would not expect from a model this size.
A Custom Tokenizer for German
Tokenization is one of those details that sounds boring but has enormous practical impact. Every token you waste on a badly split word is a token you cannot use for actual content.
We built a custom tokenizer optimized specifically for German morphology and compounding. The difference is measurable:
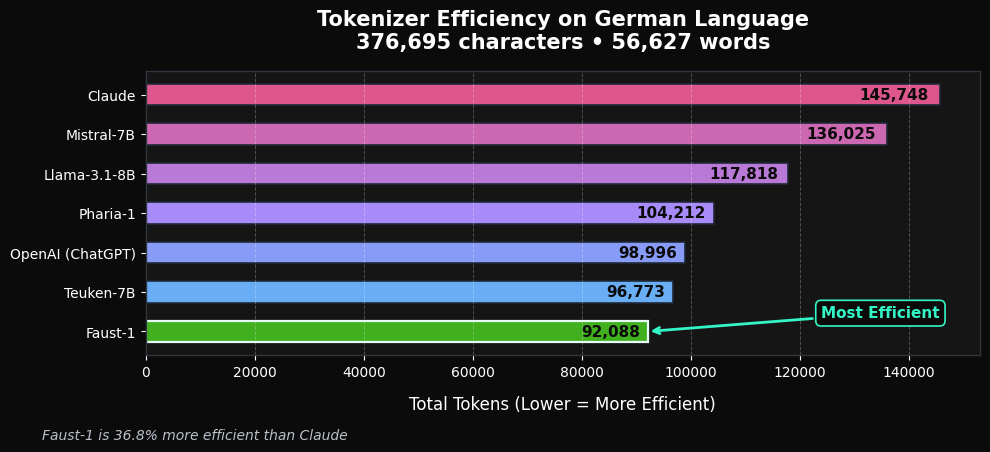
Lower token counts on German text translate directly into more usable context, lower inference cost, and less fragmentation on compound-heavy inputs. This is not a marginal improvement. On typical German text, Faust-1’s tokenizer produces significantly fewer tokens than tokenizers designed for English-first models.

Trained on Verified Synthetic Data
A substantial portion of the training signal comes from synthetic data. This is a deliberate choice, not a shortcut.
Real-world data is messy. It contains inconsistencies, labeling errors, and uneven coverage. Synthetic data, when done correctly, solves these problems. But “when done correctly” is the key phrase. Generating training data without verification produces garbage.
Our approach pairs generation with explicit verification and filtering:
- LLM-as-judge style evaluations
- Rule-based and programmatic checks
- Consistency and self-agreement filtering
This allows broad coverage of instruction-following and reasoning patterns while maintaining the quality control that makes the training signal actually useful.
Benchmark Performance
We evaluated Faust-1 on standard German-language benchmarks: ARC_de, GSM8K_de, HellaSwag_de, MMLU_de, and TruthfulQA_de.
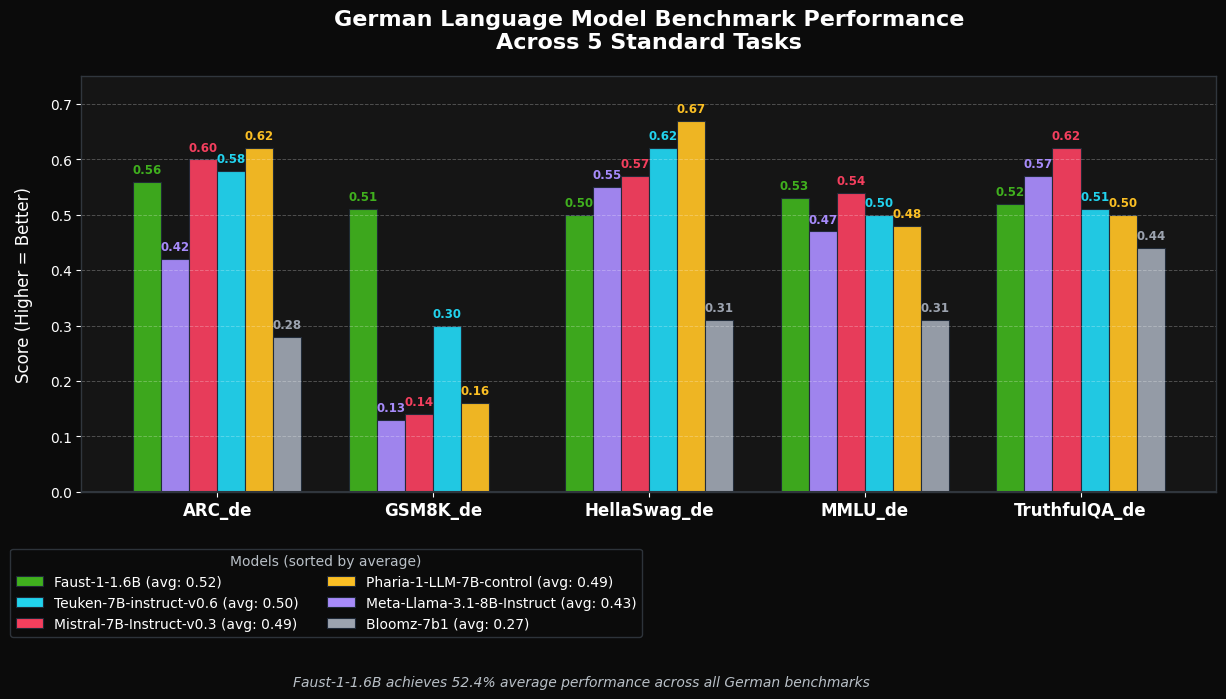
The target is best-in-class performance within the 1–2B parameter range for German-focused models. These benchmarks are straightforward to reproduce using standard Hugging Face evaluation pipelines.
Runs on Consumer Hardware
This is where Faust-1 differs most from the “bigger is better” trend in the industry.
Faust-1 is deliberately sized and optimized to run on consumer-grade hardware. No data-center GPUs required. No cloud dependency. No API costs.
Laptop or desktop (CPU or small GPU): Runs on modern CPUs or entry-level GPUs — Apple Silicon, RTX 3060/4060, RX 6600 — using optimized runtimes like GGUF, MLX, or ONNX.
Single-GPU workstation: Efficiently serves interactive workloads on a single consumer GPU with low VRAM requirements compared to larger multilingual models.
On-device and privacy-sensitive setups: Suitable for local assistants, offline document analysis, and private RAG pipelines where data must not leave the machine.
This makes Faust-1 practical for researchers, developers, and small teams who want strong German language performance without cloud dependency or high inference costs.
Quick Start
Conversational usage (recommended)
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
model_id = "tabularisai/Faust-1"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.float16,
device_map="auto",
)
messages = [
{"role": "user", "content": "Gib mir eine kurze Einführung in große Sprachmodelle (LLM)."}
]
inputs = tokenizer.apply_chat_template(
messages,
add_generation_prompt=True,
return_tensors="pt",
).to(model.device)
outputs = model.generate(
inputs,
max_new_tokens=256,
temperature=0.6,
do_sample=True,
)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))Structured output with GuideGen
Faust-1 supports structured output generation via GuideGen, our library for constrained decoding with Pydantic schemas:
pip install git+https://github.com/tabularis-ai/guidegen.gitimport guidegen as gg
from pydantic import BaseModel, Field
from typing import Literal
class EmailSummary(BaseModel):
Absender: str = Field(description="Der Name des Absenders.")
Betreff: str = Field(description="Worum geht es in der E-Mail? (max 5 Wörter)")
Zusammenfassung: str = Field(description="Kurze Zusammenfassung (max 2 Sätze).")
Prioritaet: Literal["hoch", "mittel", "niedrig"] = Field(description="Wie wichtig die E-Mail ist.")
gen = gg.GuideGen(
"tabularisai/Faust-1",
use_chat_template=True,
enable_thinking=False,
)
summary = gen.generate(prompt, EmailSummary)This means you can use Faust-1 not just for free-form conversation, but for structured extraction, classification, and any task where you need reliable JSON output.
Deployment options
vLLM (OpenAI-compatible API)
vllm serve tabularisai/Faust-1 --dtype float16SGLang
python -m sglang.launch_server \
--model-path tabularisai/Faust-1 \
--dtype float16llama.cpp (GGUF, local / on-device)
./llama-cli \
-m faust_1_q8_0.gguf \
-p "Erkläre kurz, was ein großes Sprachmodell ist."The repository includes a prebuilt Q8_0 GGUF file for efficient local inference.
Use Cases
- German conversational assistants that run locally with full data privacy
- Research and benchmarking on German NLP tasks
- Privacy-sensitive deployments where data must not leave the infrastructure
- On-device and edge experimentation with a model small enough to iterate quickly
- Structured data extraction from German documents using constrained decoding
What Comes Next
We are actively working on two follow-up variants:
- Reasoning-focused variant — enhanced chain-of-thought and multi-step reasoning for German
- Agent-oriented variant — optimized for tool use, function calling, and agentic workflows
Getting Started
- Visit the Hugging Face model page
- Accept the license terms to get access
- Try it on your own German text data
For commercial licensing, enterprise integrations, or questions, contact us at [email protected].
Community
Join our Discord to share feedback, report issues, or discuss use cases:
Faust-1 is developed by Tabularis AI in Tübingen. We build efficient, privacy-preserving AI solutions for the German language.